(defn- dispatch
[c]
(cond (nil? c) parse-eof
(identical? c *delimiter*) reader/ignore
(reader/whitespace? c) parse-whitespace
(identical? c \^) parse-meta
(identical? c \#) parse-sharp
(identical? c \() parse-list
(identical? c \[) parse-vector
(identical? c \{) parse-map
(identical? c \}) parse-unmatched
(identical? c \]) parse-unmatched
(identical? c \)) parse-unmatched
(identical? c \~) parse-unquote
(identical? c \') parse-quote
(identical? c \`) parse-syntax-quote
(identical? c \;) parse-comment
(identical? c \@) parse-deref
(identical? c \") parse-string
(identical? c \:) parse-keyword
:else parse-token))ClojureScript - Performance tuning rewrite-cljs
04 August 2015
Tags: clojure clojurescript javascript performance
TweetHow would you go about performance tuning a ClojureScript Library or a ClojureScript application ? Before I started my summer holidays I started to investigate how I should go about doing that for one of my ClojureScript libraries: rewrite-cljs I didn’t find a whole lot of info from my trusted old friend Google, so I thought I’d share some bits and bobs I’ve learned so far.
Introduction
I’ve previously blogged about how I used rewrite-cljs for two of my Light Table plugins; clj-light-refactor and parembrace The library is a ClojureScript port of the awesome rewrite-clj library by Yannick Scherer. A lot of the porting was just plain sailing with a few adaptations here and there. It’s truly great that Clojure and ClojureScript are so much aligned. After the port I also made some changes and adaptations that I knew I needed in my plugins and that I though might be useful for other use cases as well.
However one limitation that seriously nagged me was that rewrite-cljs wasn’t performant enough to be able to handle rewriting of medium to large sized files (as strings currently mind you) from Light Table.
| One of my sample ClojureScript files (about 600 lines / 20K characters) took about 250 ms to parse and build a zip for before I started looking at performance tuning. At the time of writing this blog post it’s down to 50-60 ms. Pretty good, but still need shave it down a quite a bit further to do some of the things I have in mind ! |
Opposing forces
I guess I could have started blindly changing a lot of the implementation to be closer to native JavaScript. However for several reasons I’d like to keep it as Clojur’y as possible and ideally I don’t want to stray to far away from it origins (rewrite-clj). How to balance and where to begin ?
Tools
To get some idea of where to bottlenecks were and what/if any of my optimzations had any effect I really need some tools to help me out. Fortunately Light Table ships with the chrome developer tools. The profiler is quite helpful, in addition I used a small benchmark script to see how it perfomed over a slightly longer timespan.
Tuning
First quickwin - Moving away from multimethods
Before I profiled anything I came accross a google group discussion about multimethod performance vs protocols for dispatching. The core of the parser in rewrite-cljs was pretty much a 1-1 port of the one from rewrite-clj. I decided to try to just dispatch using a cond or case.
The result was that I shaved of somewhere between 30-50 ms. I can’t remember the exact number, but it was substantial. So eventhough multimethods are nice, for this use case I don’t think they added that much value and the performance overhead (due to indirection?) just wasn’t justified. I did try using both a map and case for char tests, but found that a simple cond outperformed both (on my machine running on an old ClojureScript version in Light Table)
Some random pickings
When working with Light Table I’ve previously found that in some cases I could gain some nice performance improvements by changing from clojure datastructures to native js. I’ll show a couple of samples
Checking for token boundaries
(defn boundary?
[c]
"Check whether a given char is a token boundary."
(contains?
#{\" \: \; \' \@ \^ \` \~
\( \) \[ \] \{ \} \\ nil}
c))was rewritten to:
(def js-boundaries (1)
#js [\" \: \; \' \@ \^ \` \~
\( \) \[ \] \{ \} \\ nil])
(defn boundary?
[c]
"Check whether a given char is a token boundary."
(< -1 (.indexOf js-boundaries c))) (2)| 1 | Figured the list of boundaries only needs to be defined once |
| 2 | Using JavaScript Array.indexOf proved to be quite efficient. More so than a ClojureScript map lookup in this case. |
I used a similar approach for other kinds of boolean tests for characters (whitespace?, linebreak? etc).
Testing characters for equality
Tests like:
(when (= c "\")
... )Performs better using identical? (same object):
(when (identical? c "(")
... )Still far from satisfied - swanodette to the rescue
In the end of june/beginning of july I noticed that Davin Nolen was tweeting about promising performance improvments with regards to cljs-bootstrap. This made me curious and eventually I found some very inspiring commits on a cljs-bootstrap branch of a fork of tools.reader. Hey, surely this guy nows a thing or two about what really might help and still keep the code nice and clojury.
So I just started picking from relevant commits on this branch
A few highlights:
Avoiding protocol indirection
(defn peek
"Peek next char."
[^not-native reader] (1)
(r/peek-char reader))| 1 | not-native is a type hint that inline calls directly to protocol implementations |
Type hinting
(defn ^boolean whitespace? (1)
[c]
(r/whitespace? c))| 1 | The boolean type hint allows the cljs compiler to avoid emitting a call to cljs.core/truth_. The type hint is really for true boolean values (true/false), but if we know for sure that the value
isn’t one of 0, "" (empty-string) and NaN we can coerce the compiler to do our bidding ! |
satisfies? ⇒ implements?
Changing:
(if (satisfies? IWithMeta o)
...)To:
(if (implements? IWithMeta o)
...)Helps quite a bit.
2X+ performance increase, what now ?
We’ve achieve quite a bit, but it’s still between 100-120 ms for my sample. I need more. More I tell you !
So back to the profiler to try and pick out some suspicious candidates.
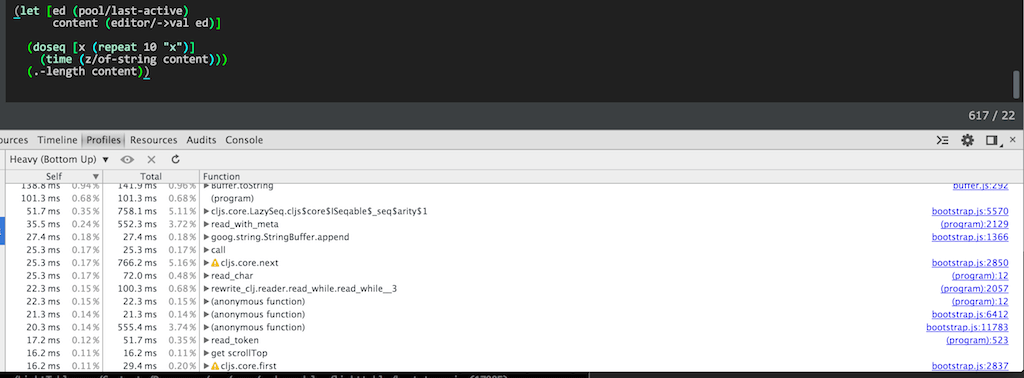
I made various micro-improvements like changing
-
str to goog.stringbuffer for concatinating strings
-
aget to .charAt for getting a character at a position in a string
-
Stringbuffer initialization to occur once and using clear inside functions (felt a bit like global variables (: )
-
count to .length for string length
-
etc
It all helped a bit, steadily shaving of a millisecond here and a millisecond there (even had some setbacks along the way !).
Do’s and Don’ts
A couple of function showed a lot of own-time in the profiler. I really couldn’t figure out why though. They didn’t seem to do much, but delegate to other functions. I tried a range of things until I stumbled accross this blogpost by Stuart Sierra. Both of the methods was using the following pattern for handling a single var-arg:
(defn token-node
"Create node for an unspecified EDN token."
[value & [string-value]] (1)
(->TokenNode
value
(or string-value (pr-str value))))| 1 | & [string-value] destructures the sequence of arguments |
This constructor method was called a lot. So not only was this perhaps not ideal stylewise, but it turns out it has some pretty bad performance characteristics as well. (Not knowing the details, I can only speculate on why…)
So I changed the above code to:
(defn token-node
"Create node for an unspecified EDN token."
([value]
(token-node value (pr-str value)))
([value string-value]
(->TokenNode value string-value)))Yay! Changing two frequently called functions to use method overloading had a huge impact on performance. Not only that, but I noticed that the garbage collector was using substantially less time as well.
Summary
Performance tuning is fun, but really hard. Not knowing anything about the inner wokings of ClojureScript and the closure compiler doesn’t help. There wasn’t much to be found in terms of help using my normal search foo, and the book "Performance tuning ClojureScript" hasn’t been seen quite yet. That beeing said, this is probably the first time in over a year and half playing/working with ClojureScript that I’ve even thought about performance issues with ClojureScript. Mostly it’s a non issue for my use cases.
Quite a few of the tweaks didn’t really make the code that much less idiomatic, however there were a couple of cases where the host language seeps out.
Feel free to share you experiences with performance tuning ClojureScript. I’d really like to learn more about it and hopefully make some additional shavings in rewrite-cljs !
| rewrite-cljs 0.3.1 was just released. Snappier than ever |